
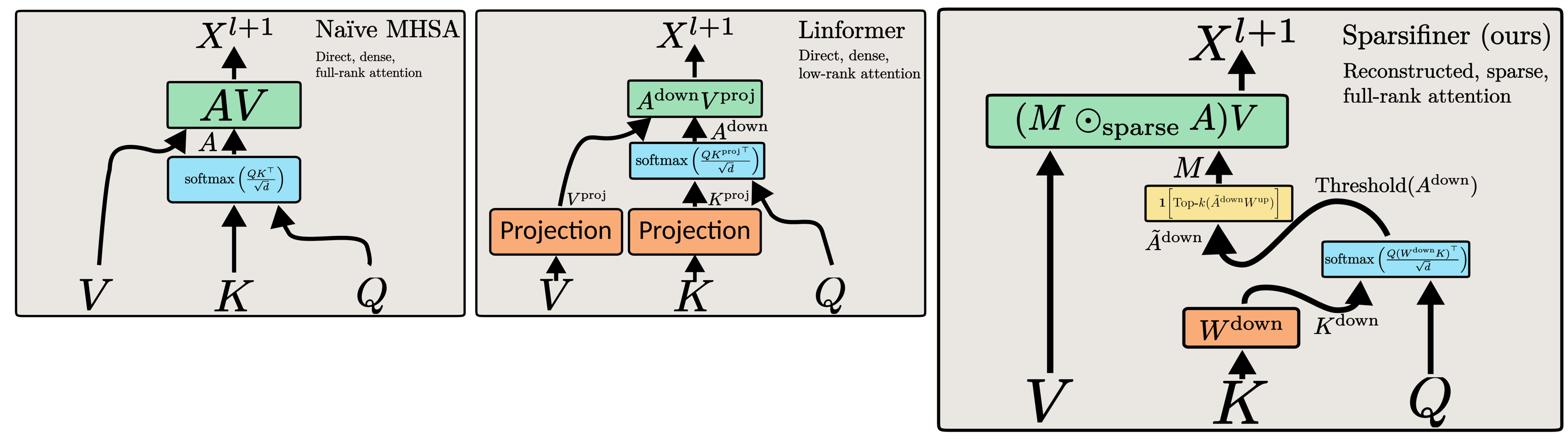
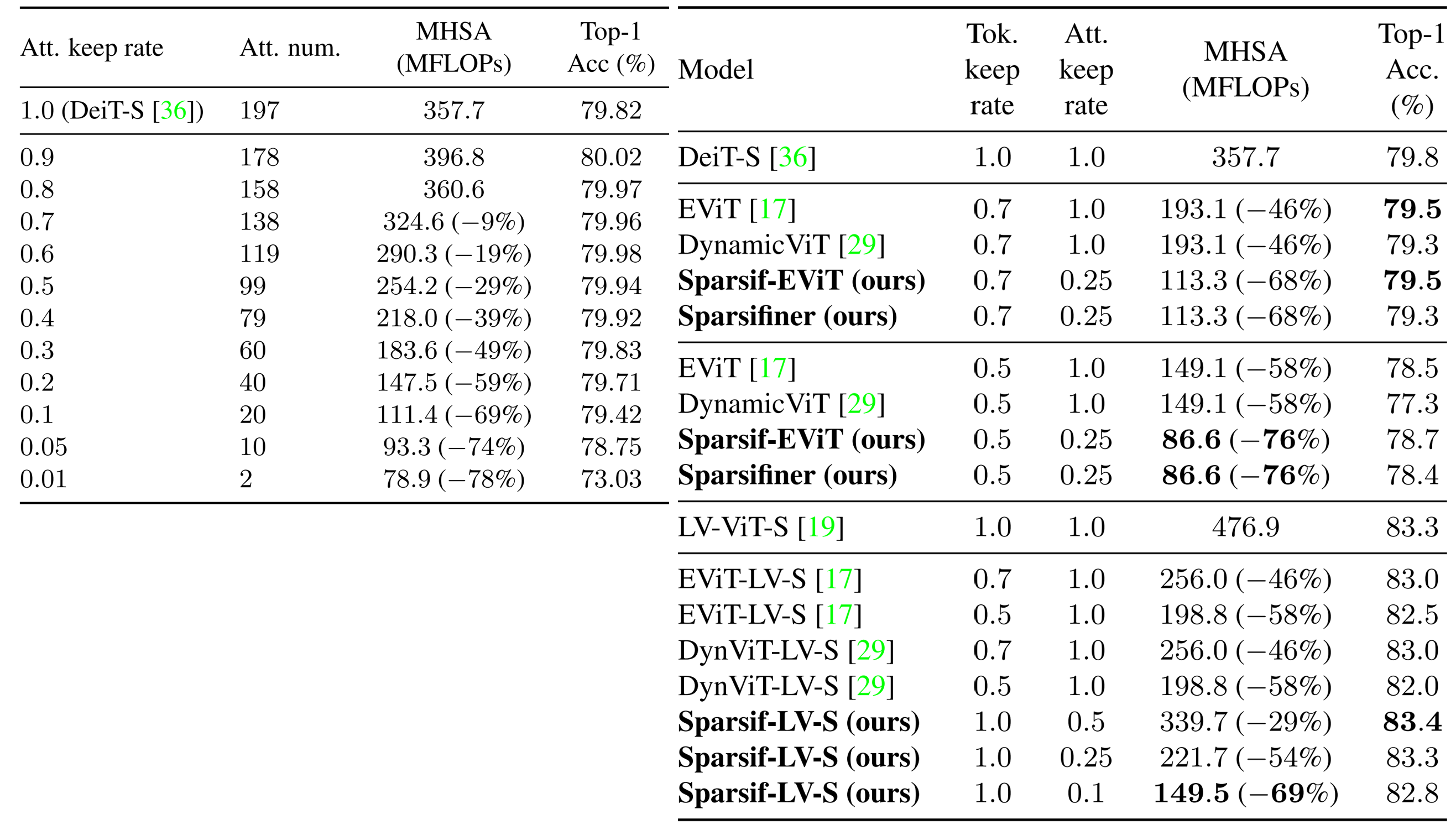
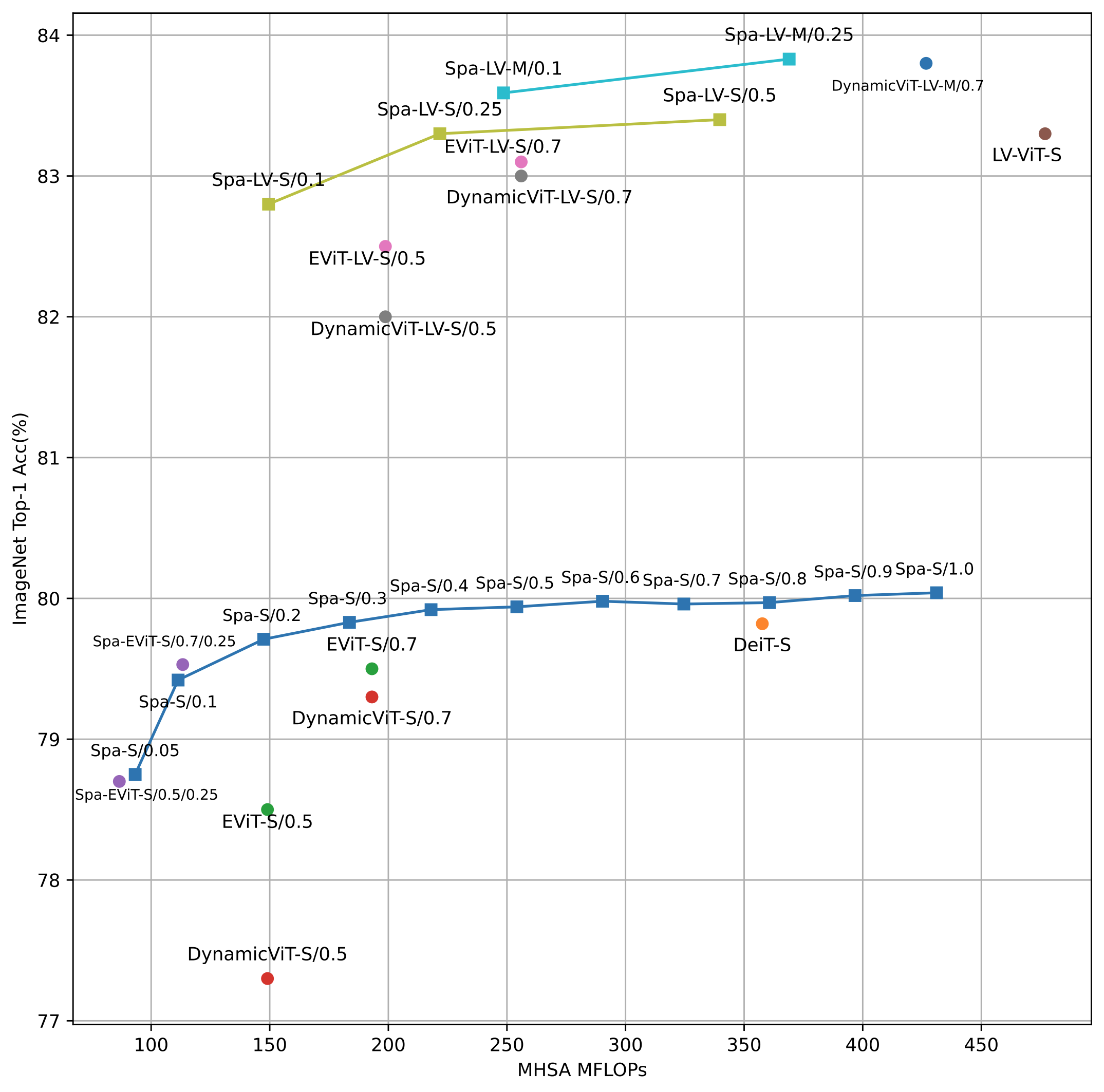
Vision Transformers (ViT) have shown competitive advantages in terms of performance compared to convolutional neural networks (CNNs), though they often come with high computational costs. To this end, previous methods explore different attention patterns by limiting a fixed number of spatially nearby tokens to accelerate the ViT’s multi-head self-attention (MHSA) operations. However, such structured attention patterns limit the token-to-token connections to their spatial relevance, which disregards learned semantic connections from a full attention mask. In this work, we propose an approach to learn instance-dependent attention patterns, by devising a lightweight connectivity predictor module that estimates the connectivity score of each pair of tokens. Intuitively, two tokens have high connectivity scores if the features are considered relevant either spatially or semantically. As each token only attends to a small number of other tokens, the binarized connectivity masks are often very sparse by nature and therefore provide the opportunity to reduce network FLOPs via sparse computations. Equipped with the learned unstructured attention pattern, sparse attention ViT (Sparsifiner) produces a superior Pareto frontier between FLOPs and top-1 accuracy on ImageNet compared to token sparsity. Our method reduces 48% ∼ 69% FLOPs of MHSA while the accuracy drop is within 0.4%. We also show that combining attention and token sparsity reduces ViT FLOPs by over 60%.



@InProceedings{Wei_2023_CVPR,
author = {Wei, Cong and Duke, Brendan and Jiang, Ruowei and Aarabi, Parham and Taylor, Graham W. and Shkurti, Florian},
title = {Sparsifiner: Learning Sparse Instance-Dependent Attention for Efficient Vision Transformers},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {22680-22689}}